Клетки смысла
Глава 2. Парадокс: один нейрон модели думает о лягушках, Канаде и знаке вопроса одновременно — и это не баг, а конструктивная необходимость. Посмотрим, как из каши выделить чистые клетки
Цели урока
К концу этого урока вы:
- Что такое фича — клетка-детектор на одно понятие — и чем она отличается от «сырого» нейрона
- Почему один нейрон вспыхивает на несвязанные понятия (полисемантичность) и зачем модели вообще это нужно
- Что такое суперпозиция и почему это геометрическая необходимость, а не ошибка
- Как «словарное обучение» распутывает нейроны в чистые фичи
- Где пределы этого метода — честно

Смотри сюда внимательно — вот тут вся соль.
Клетки смысла
Представьте: вы открываете атлас человеческого тела и видите клетку, которая одновременно отвечает за зрение, переваривание жиров и ориентацию в пространстве. Один клеточный тип — три несвязанные функции. Биолог бы решил, что атлас испорчен. Но именно так устроен мозг большой языковой модели: один нейрон загорается и на «лягушку», и на «Канаду», и на знак вопроса — понятия, между которыми нет ничего общего.
Это не ошибка в проектировании. Это следствие жёсткого ограничения: понятий в языке несравнимо больше, чем нейронов в сети. Чтобы поместить все смыслы в ограниченное число ячеек, природа (точнее, обучение) нашла хитрость: упаковать несколько понятий в один нейрон, используя их как разные направления в пространстве. В первой главе мы говорили о микроскопе [1]. Теперь посмотрим, что он показывает — и почему первая же клетка под стеклом оказалась совсем не такой простой, как ожидалось.
Что вы поймёте после этой главы
- Что такое фича — клетка-детектор на одно понятие — и чем она отличается от «сырого» нейрона
- Почему один нейрон вспыхивает на несвязанные понятия (полисемантичность) и зачем модели вообще это нужно
- Что такое суперпозиция и почему это геометрическая необходимость, а не ошибка
- Как «словарное обучение» распутывает нейроны в чистые фичи
- Где пределы этого метода — честно
Часть 1. Что такое фича — и зачем она нужна
Возьмём конкретный образ из первой главы: фича — это клетка-детектор на одно понятие. Клетка зрительного нерва возбуждается на свет определённой длины волны. Клетка-детектор «Золотые Ворота» возбуждается, когда в тексте появляется этот мост, его фотография, его название. Она не реагирует на другие мосты, другие города, другие достопримечательности — только на свой объект. Одно понятие, один детектор.
Это идеал. Его называют моносемантичным нейроном: от греческого «моно» (один) и «семантика» (смысл). Такие клетки — мечта натуралиста: нашёл одну, понял, за что она отвечает, нанёс на анатомический атлас. Готово.
Проблема в том, что большинство нейронов модели — не такие. Исследователи из Anthropic, проверяя сырые нейроны, обнаружили, что один и тот же нейрон реагирует на совершенно несвязанные вещи: например, на «лягушек», «Канаду» и «знак вопроса» [2]. Не родственные понятия, не синонимы — просто три случайно соседствующих кластера. Такой нейрон называют полисемантичным: у него много значений, и они никак не связаны. Такую клетку в атлас не занесёшь.
Часть 2. Суперпозиция — природная хитрость упаковки
Ответ на вопрос в жёлтой карточке выше — математический. Представьте комнату с тысячей полок. Вам нужно разместить миллион книг. Единственный выход — класть несколько книг на одну полку. Именно это делает нейронная сеть.
У модели Claude, с которой работали в Anthropic, примерно 4 тысячи нейронов в каждом слое. А различимых понятий, которые модель освоила из текстов всего интернета, — десятки миллионов. Разрыв в тысячи раз. Поместить каждое понятие в свой отдельный нейрон физически невозможно.
Решение, которое нашло обучение, называется суперпозиция [4]. Это геометрический трюк: в многомерном пространстве можно разместить много «почти-перпендикулярных» направлений, которые будут почти не мешать друг другу. Редкие понятия — те, которые в тексте встречаются редко и крайне редко стоят рядом, — можно запаковать в одно направление. Если «лягушки» и «Канада» в учебном тексте никогда не встречались вместе, то небольшое пересечение их направлений в нейроне почти не вредит качеству ответов.
Эффект оказался не просто теоретической возможностью — он был предсказан и изучен в работе 2022 года [4]. Авторы показали: если понятий много, а нейронов мало, обучение само находит суперпозицию, потому что это лучший компромисс между ёмкостью и точностью. Полисемантичность нейрона — не глюк, а оптимальная упаковка.
Часть 3. «Распутывание» — как сделать чистые клетки из каши
Итак, у нас на стекле — клетки-каши. Один нейрон загорается на три несвязанных понятия. Как натуралисту разглядеть что-то осмысленное? Метод называется словарное обучение (dictionary learning).
Представьте, что вы приехали в библиотеку, где книги стоят вразнобой: детективы вперемешку с поваренными, учебники — с поэзией. Вам нужно разобраться, что где. Словарное обучение — это алгоритм, который берёт хаотичные активации нейронов и ищет в них скрытые направления, каждое из которых отвечает за одно понятие [2].
Результат называется разреженным автокодировщиком (sparse autoencoder). Он принимает шумный сигнал от тысяч нейронов и выдаёт набор фич — чистых клеток-детекторов. Каждая фича активируется редко и сильно: только когда её понятие действительно есть в тексте. Большинство времени она молчит. Это «разреженность» в её названии.
Пример, который вошёл в учебники. В 2024 году исследователи применили словарное обучение к модели Claude 3 Sonnet и нашли миллионы таких фич [3]. Одна из них — вы уже знаете какая: детектор «Золотые Ворота». Из каши активаций вырезалась чистая клетка — со своей специализацией, своим порогом, своей реакцией.
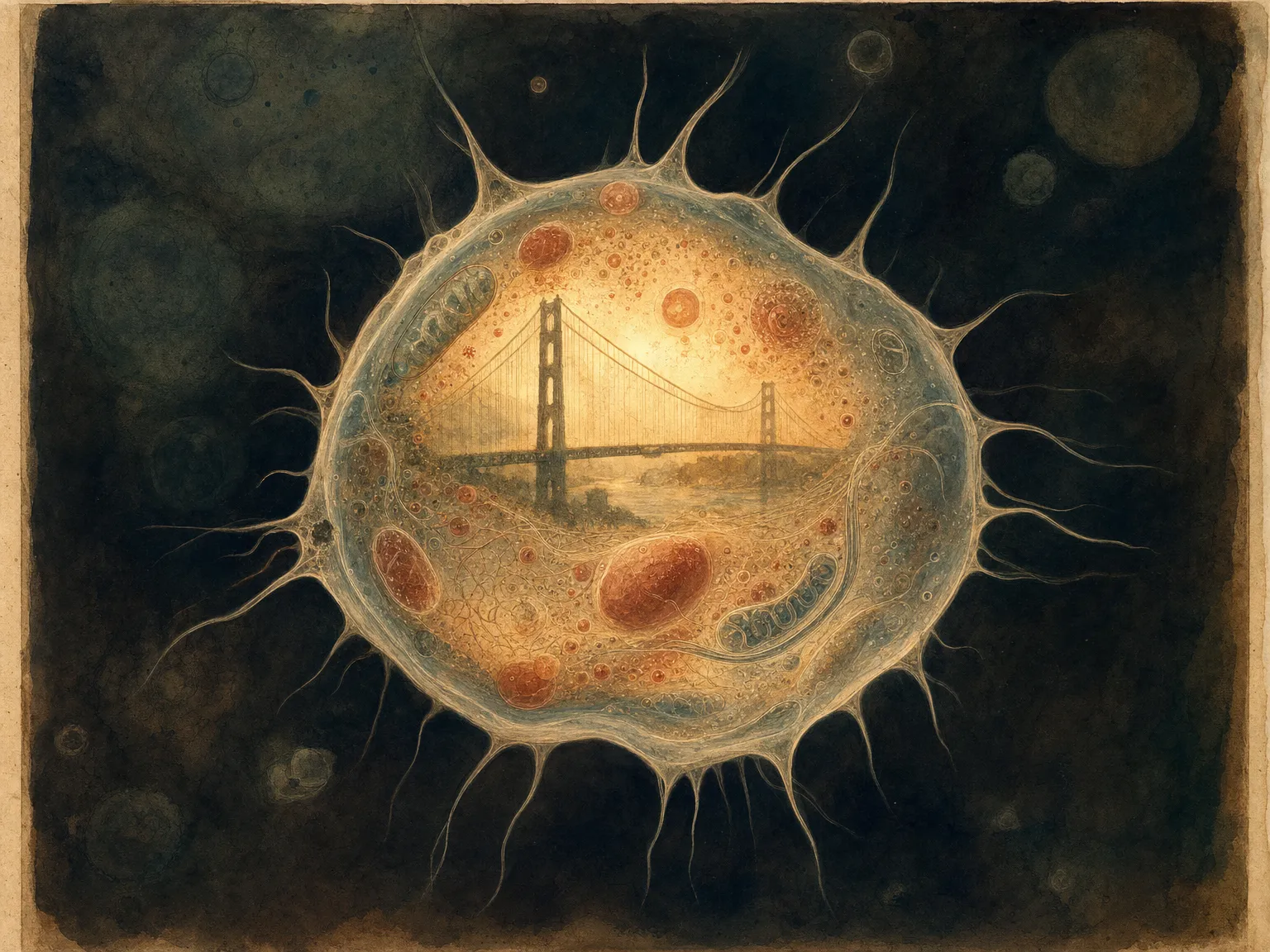
Часть 4. Разглядываем клетку вблизи
Что именно мы видим, когда нашли фичу? Посмотрим на структуру одной клетки-детектора — той, что оказалась самой знаменитой в истории интерпретируемости.
Объект реакции
Мост Золотые Ворота в Сан-Франциско — изображения, слова «Golden Gate», упоминания пролива и тумана над ним.
Разреженность
Фича молчит почти всегда. Загорается только когда понятие действительно присутствует в тексте — не на все слова о мостах, не на все упоминания Калифорнии.
Причинность
Если зонд усиливает фичу принудительно — вся речь модели сворачивает к Золотым Воротам. Это не корреляция, а рычаг.
Связи с другими фичами
У фичи есть соседи: детекторы «Сан-Франциско», «туман», «мост». Вместе они образуют кластер — будущую цепь из Главы 3.
Часть 5. Честно о пределах препарата
Фичи — это наша реконструкция, а не «настоящие клетки» модели. Вспомним из первой главы: препарат — это чучело, удобная копия [1]. Сама модель никогда не «думала» фичами как чем-то самостоятельным. Словарное обучение — это наш способ смотреть на неё, а не её способ думать. Важно не путать карту с территорией.
что работает
Фичи причинно участвуют в поведении — это доказано вмешательством. Найденные детекторы читаемы человеком и воспроизводимы.
что работает
Словарное обучение масштабируется: Templeton et al. 2024 нашли миллионы интерпретируемых фич в Claude 3 Sonnet [3].
ограничения
Не все найденные фичи интерпретируемы человеком. Часть остаётся «тёмной материей» — активируется на что-то, но на что именно — непонятно.
ограничения
Распутывание неполное. Суперпозиция убрана не вся: некоторые фичи всё ещё полисемантичны. Микроскоп грубоват — как в Главе 1.
Правильный ответ — в, но гипотезу (а) никто формально не опроверг.
Итог: что мы нашли в клетках
Нейрон — не клетка. Клетка — фича. Нейроны полисемантичны по математической необходимости: понятий в языке неизмеримо больше, чем нейронов. Обучение упаковывает их в суперпозицию — почти-перпендикулярные направления в многомерном пространстве. Словарное обучение распутывает эту упаковку и выдаёт чистые клетки-детекторы — фичи, каждая со своей специализацией.
Эти фичи — первый уровень анатомии: отдельные клетки, каждая на своём предметном стекле. Но один детектор «Золотые Ворота» — ещё не мышление. Мышление начинается, когда клетки соединяются и работают цепью.
В следующей главе. Берём набор чистых фич и смотрим, как они соединяются в цепь — нервный путь одной мысли. Главный пример: вопрос «столица штата, где Даллас?» — как модель внутри сначала зажигает «Техас», потом «Остин», и как вмешательство в промежуточный шаг доказывает, что рассуждение настоящее. Это анатомический атлас одной мысли.
Источники этой главы
- PrimaryLindsey, J., Gould, E., Lindsay, J., et al. / Anthropic (2025). On the Biology of a Large Language Model. transformer-circuits.pub.
- Peer-reviewedBricken, T., Templeton, A., Batson, J., et al. / Anthropic (2023). Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. transformer-circuits.pub.
- Peer-reviewedTempleton, A., Conerly, T., Marcus, J., et al. / Anthropic (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. transformer-circuits.pub.
- FoundationalElhage, N., Henighan, T., Joseph, N., et al. / Anthropic (2022). Toy Models of Superposition. transformer-circuits.pub.
Глава информационно-просветительская. Это рассказ об идеях исследования, а не техническое руководство по машинному обучению.